 FLITE Citations & Tools
Citations & ToolsFLITE Citations & Tools
Citations & Tools
FLITE Citations & Tools
Citations & ToolsFLITE Citations & Tools
Citations & Tools
AI's put tiny pieces of information together like a puzzle.
Understanding just a few things about how Generative Artificial Intelligence functions is crucial to identifying student writing created by one.
Generative AIs are trained on datasets. There are datasets for the Large Language Model (LLM) AIs such as ChatGPT and datasets for the image AIs such as DALL-E.
Most of the AIs a student might use (of one type):
**NOTE**
- Update from April 2024 -
The game is changing - some AI LLMs are now purchasing content from paid datasets. Most search engines now include some sort of AI (the quality varies) and soon there will be an AI presence in library resources as well.
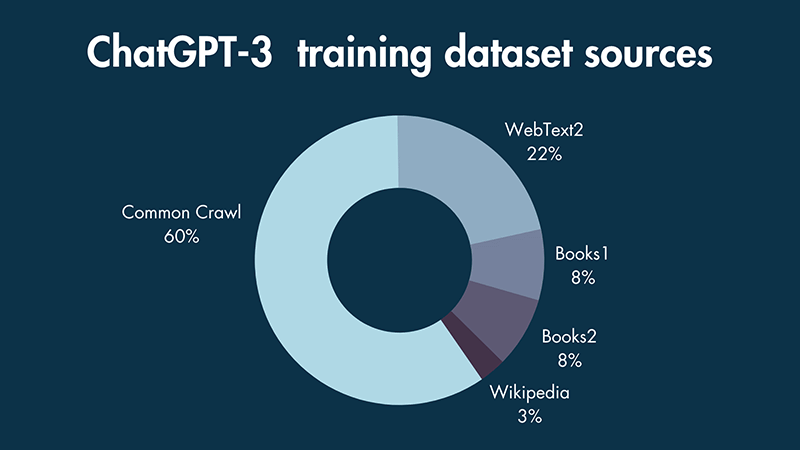
https://www.stylefactoryproductions.com/wp-content/uploads/2023/04/chatgpt-3-training-dataset-sources.png
A Generative AI system pulls together many pieces of information called tokens that seem to match each other. This process is called tokenization.
Just because the tokens seem to match does not mean that they correctly match.
The ball rolled down the __________? What would you say?
Road?
Mountain?
Slope?
Street?
Slide?
Obviously it should have been hill? But what if hill wasn't right?
